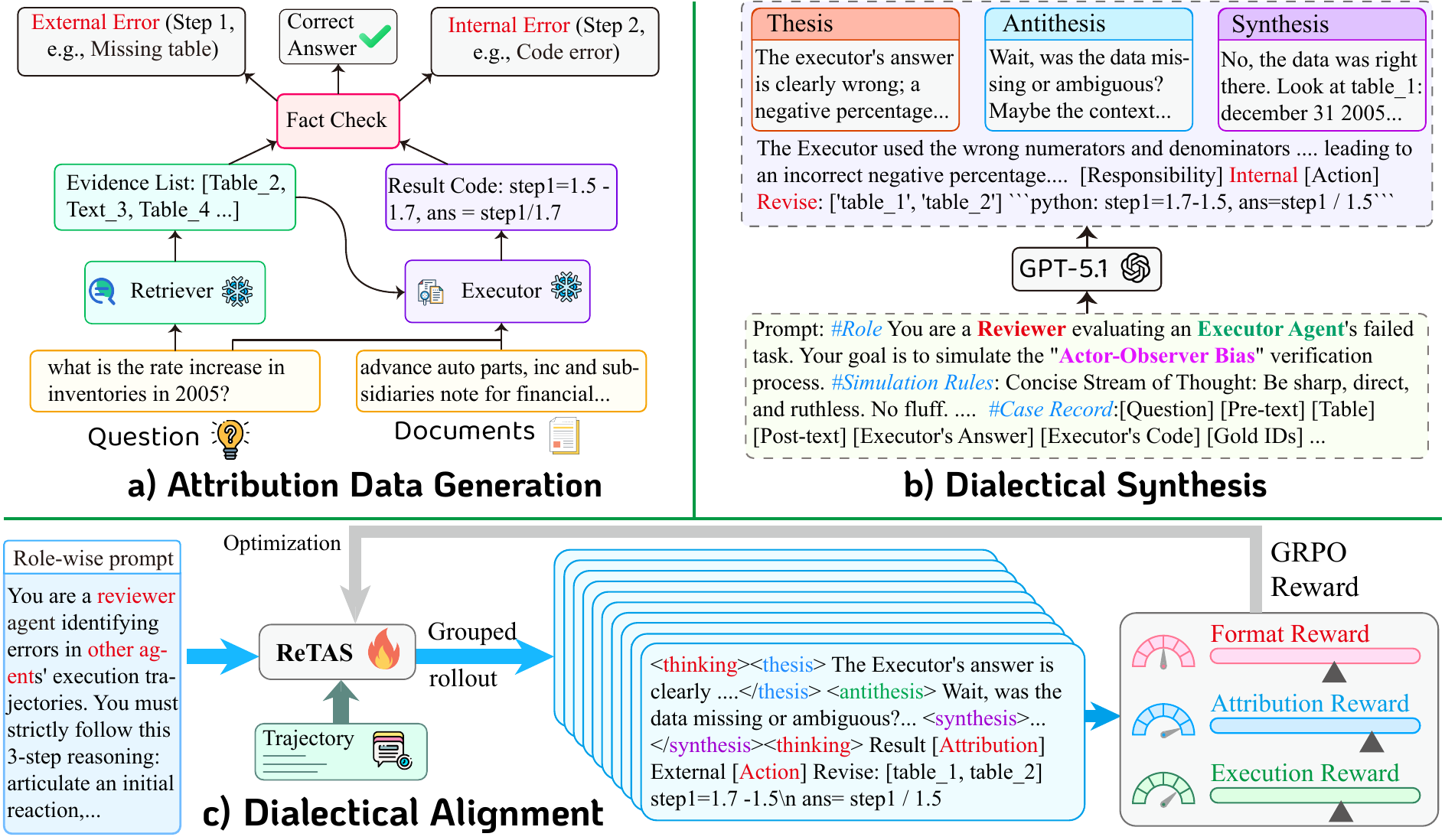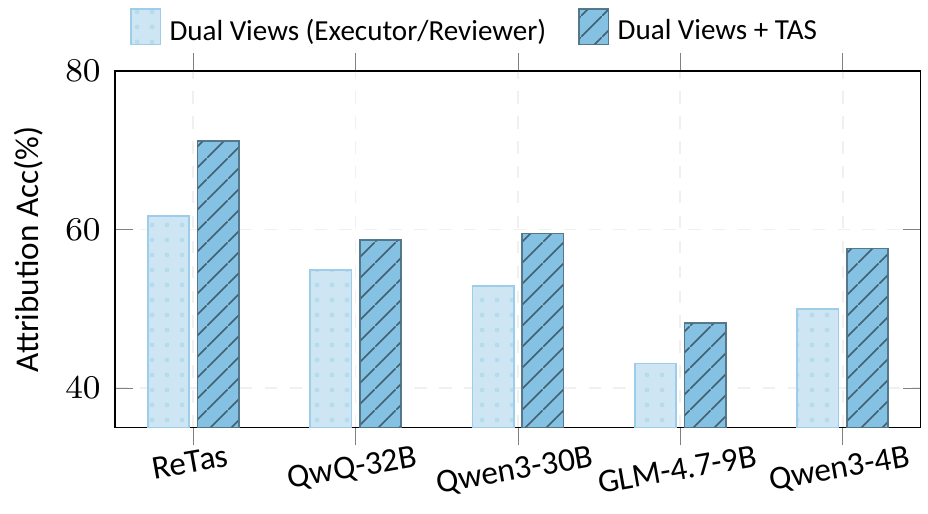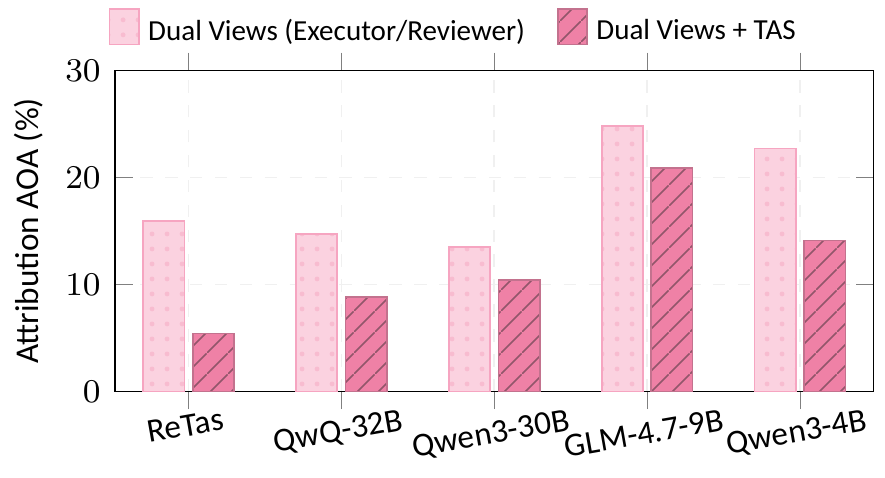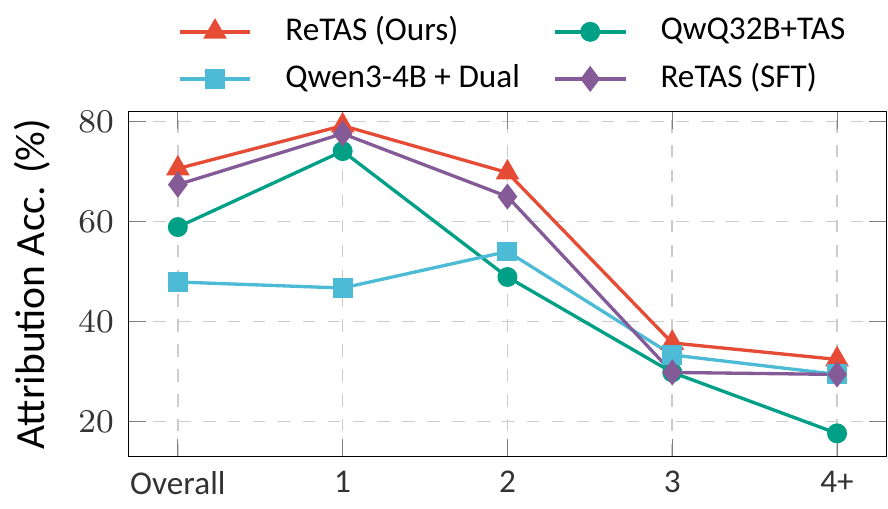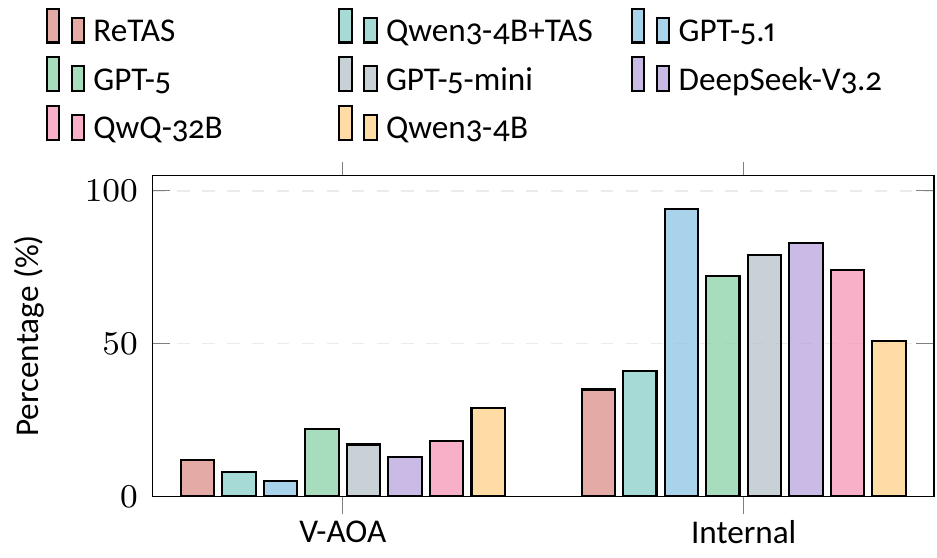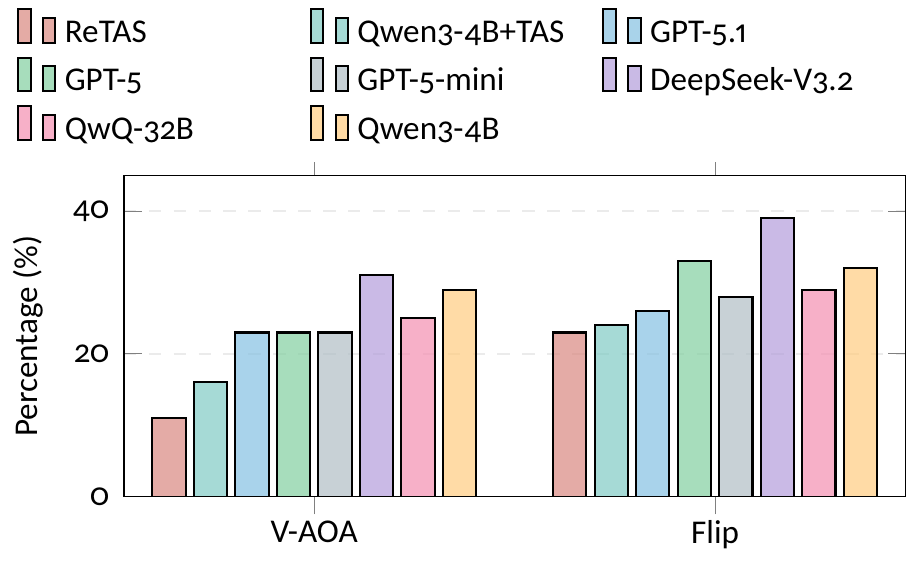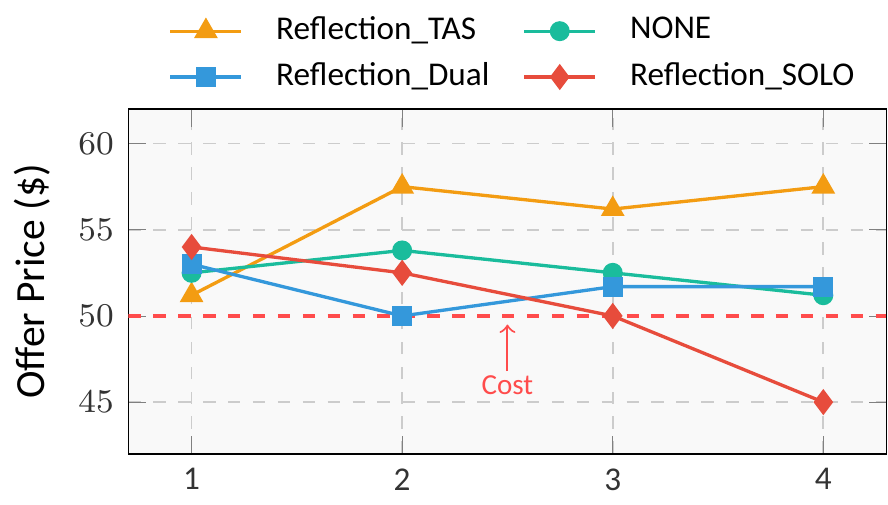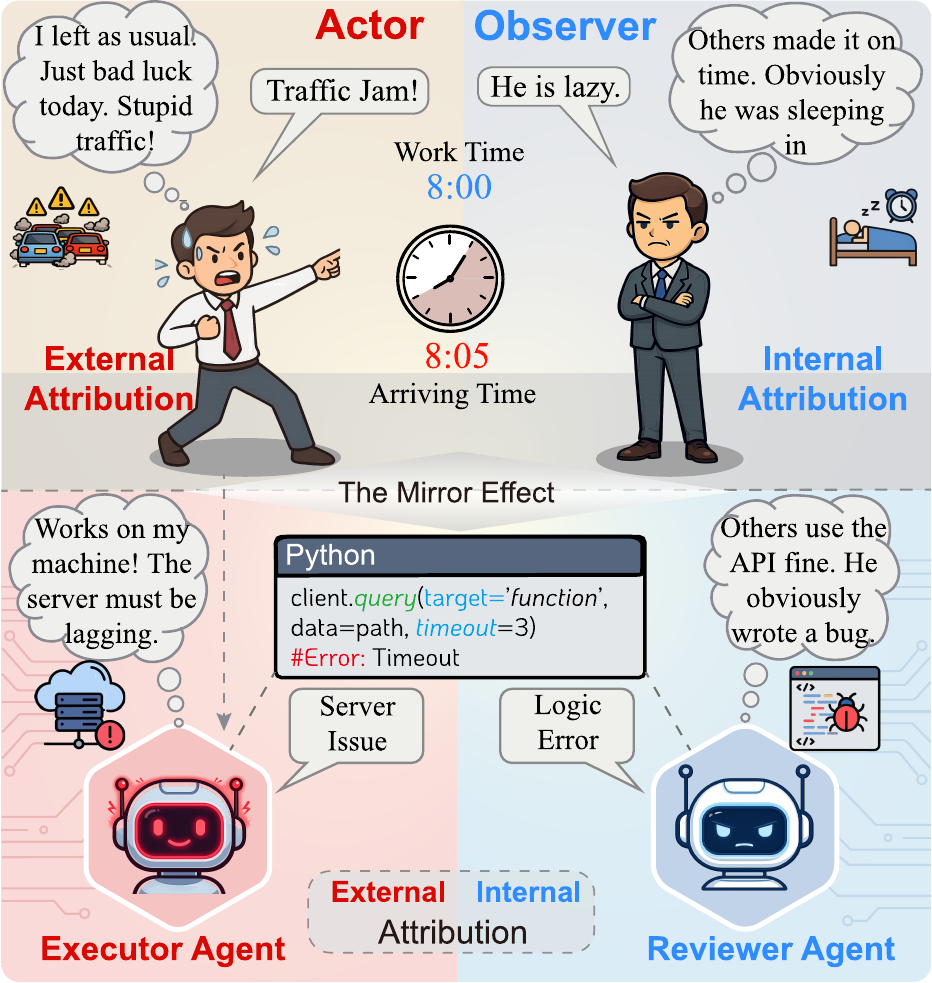
Three stages inspired by Fichtean dialectics:
- Thesis: Role-congruent explanation expressing the agent's expertise.
- Antithesis: Opposing perspective to expose blind spots.
- Synthesis: Evidence-grounded conclusion integrating both views.
Trained via SFT + GRPO with three-component reward: format (1/7), attribution (2/7), execution (4/7).